 The NYPL Registry
The NYPL Registry
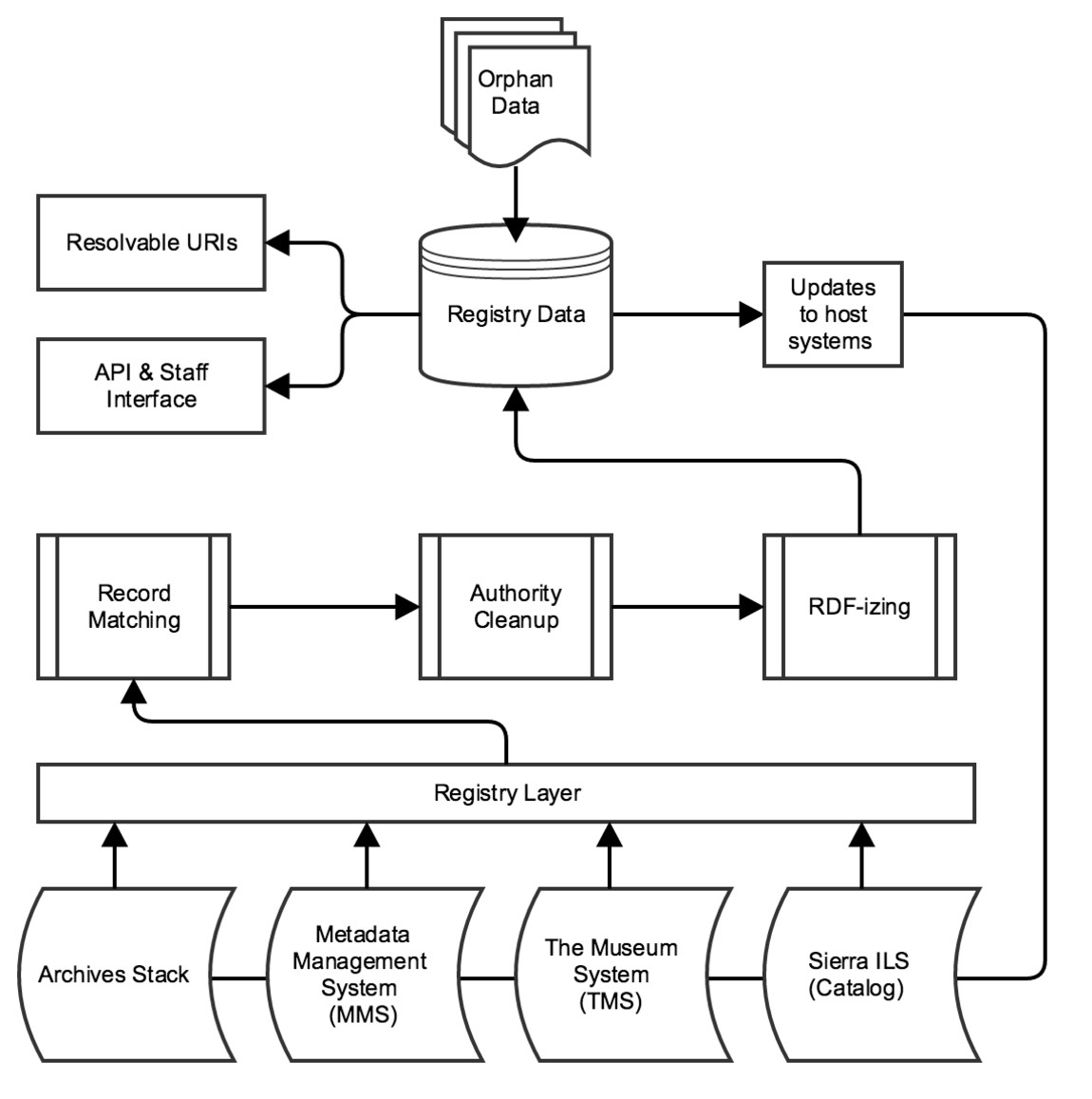
NYPL manages one of the broadest ranges of cultural heritage materials, art, and artifacts in the country across a network of diverse curatorial divisions. The organization, management, and description of these resources, however, vary by division, impeding our abilities to provide quality discovery experiences for our users across the web. Additionally, many of our resources have never been cataloged or have only been recorded in print indexes, meaning that users may only discover them through a visit to a reading room, a conversation with a curator, or through word of mouth.
We have more than ample opportunity to improve discovery, but to establish the library’s presence and authority on the web, we must prove our unique value beyond being just another provider of content. To inspire lifelong learning, advance knowledge, and strengthen our communities on the web, we must extend the library’s walls using the web’s languages and tools. People use information as evidence, as education, for personal enrichment, and for entertainment, and they usually find it on the web before using the library website. Users may often initiate a search with a keyword in a box, but much of discovery is driven by networks of users, through referrals and conversation (Tumblr, Facebook, Twitter), reviews (Yelp, Amazon, Metafilter), relatedness (Wikipedia, Amazon "also bought/viewed", YouTube), ratings (Reddit, Stack Exchange, any newspaper article's comment section). To promote our resources across user networks they must be easily and consistently identifiable, embeddable, shareable, persistent, they, of course, must point to something useful.
We propose a registry system to give unique web identifiers (URIs) to every resource in our collections, which people may use in their conversations and interactions across the web. These identifiers will also serve as the subjects of linked data "statements," metadata assertions (both bibliographic and beyond) that can be aggregated in any number of ways to give different record-like views of a resource. The web addresses of these identifiers can resolve to separate web pages for humans and computers. The human-friendly interface to this data could provide bibliographic information, curator and staff annotations, crowdsourced information, and links to connected related resources and concepts from across the linked data graph. The computer-readable page would provide developers, systems, and search engines with machine-actionable data about the resource as well as an easily-traversable map to related resources and concepts.
In addition to leveraging the web as a platform for promoting our resources, we can offer our own platform for our users to describe, enhance, share, and add value to our resources. While libraries have exercised expert control over subject access, our users converse in many languages and fluid vernaculars that often bear little resemblance to our authoritative terms. Our descriptions, which provide basic access within our catalogs, also frequently fall short in the depth of description desired within narrower domains and communities. Our users are experts in many domains and can help contribute descriptions and links that we do not have the resources or expertise to provide. We can empower staff and users to enhance our bibliographic descriptions with their own knowledge. We can invite them to establish links between our resources and those in other libraries and beyond. We can enable them to curate sets of resources to share and reuse. We can build our own pillars of knowledge by establishing and hosting authoritative identifiers for concepts in particular areas of expertise, such as photographers, performing arts productions, and New York building footprints. (Tracking and sharing the provenance of these assertions will allow users to distinguish between library-created or vetted data and user-generated data to make their own judgments on value and credibility.)
The open and extensible nature of the RDF framework will enable us to model a system for identifying our resources and structuring the data about them in a way that will be openly accessible on the web. Reusing established and emerging ontologies and vocabularies, such as PCDM, Dublin Core terms, BIBFRAME for bibliographic data and SKOS for defining authorities and thesauri will ensure our data can converse with other linked data on the web.
Featured Pages
Filter by label
There are no items with the selected labels at this time.
Recently Updated Pages